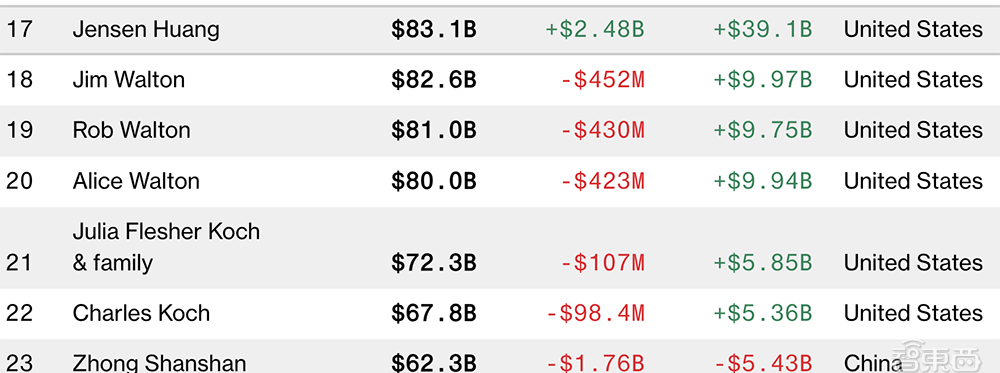
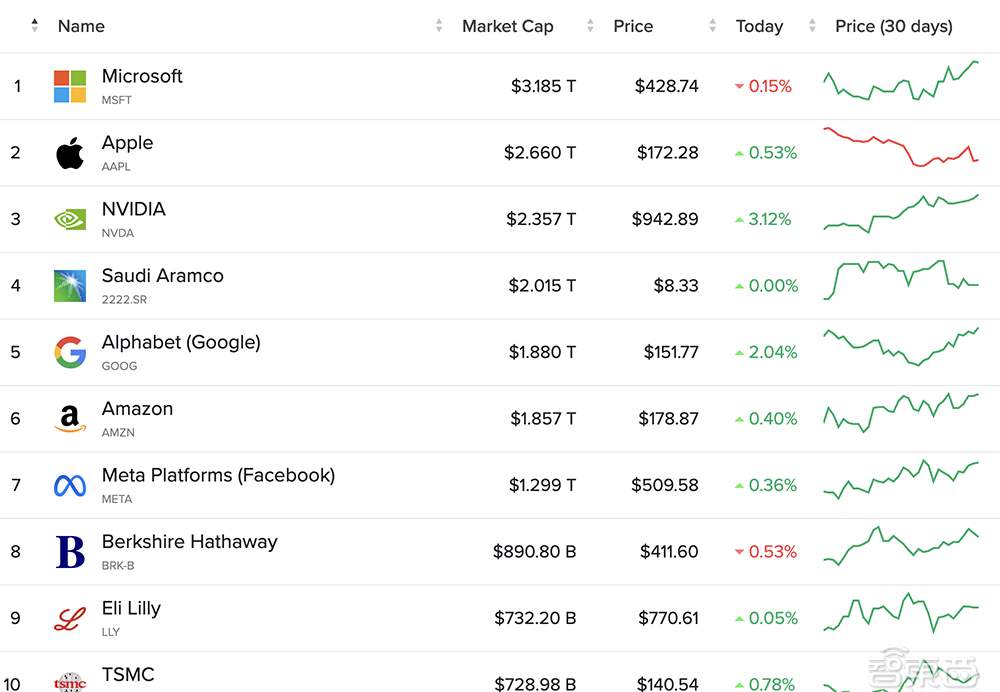
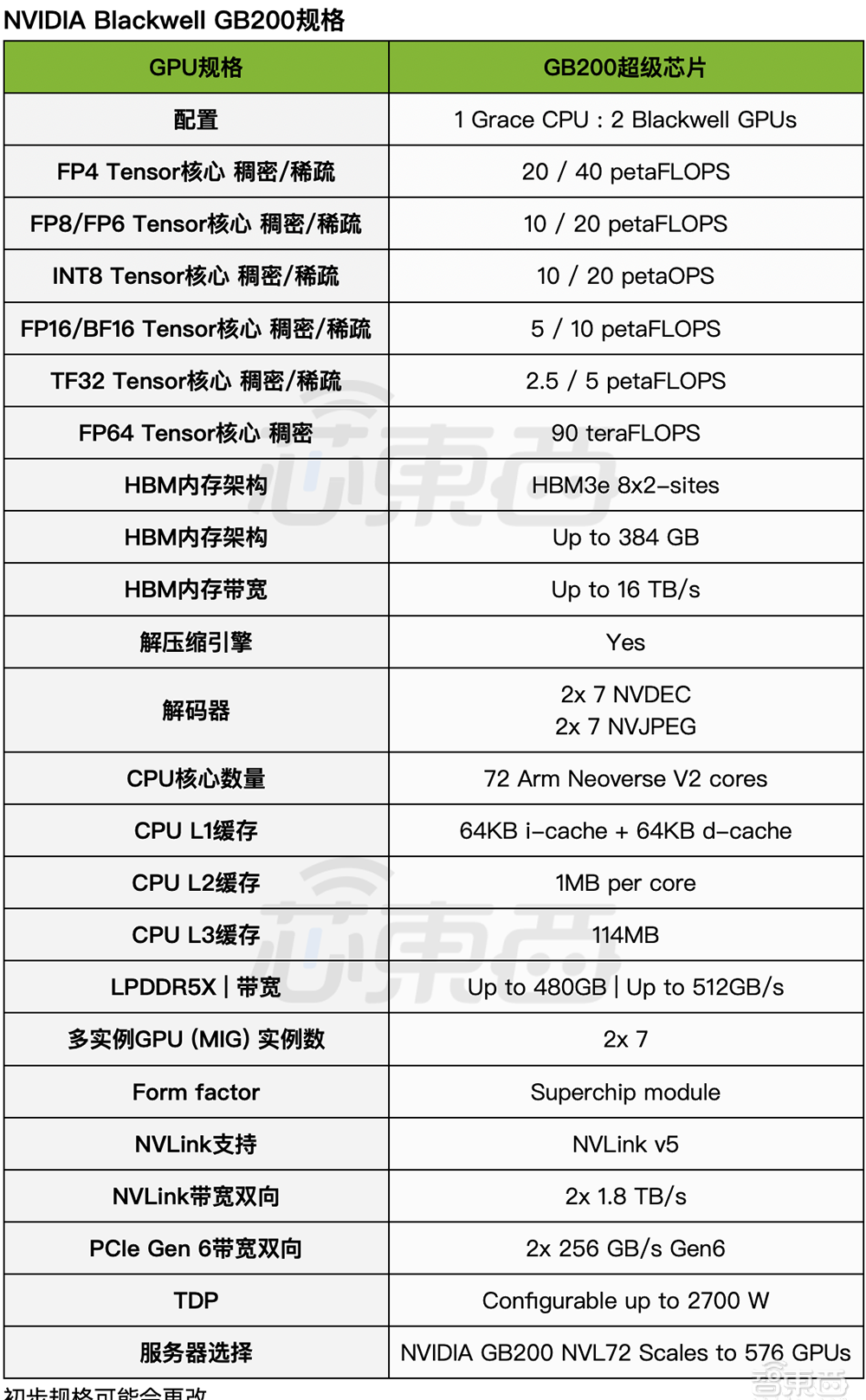
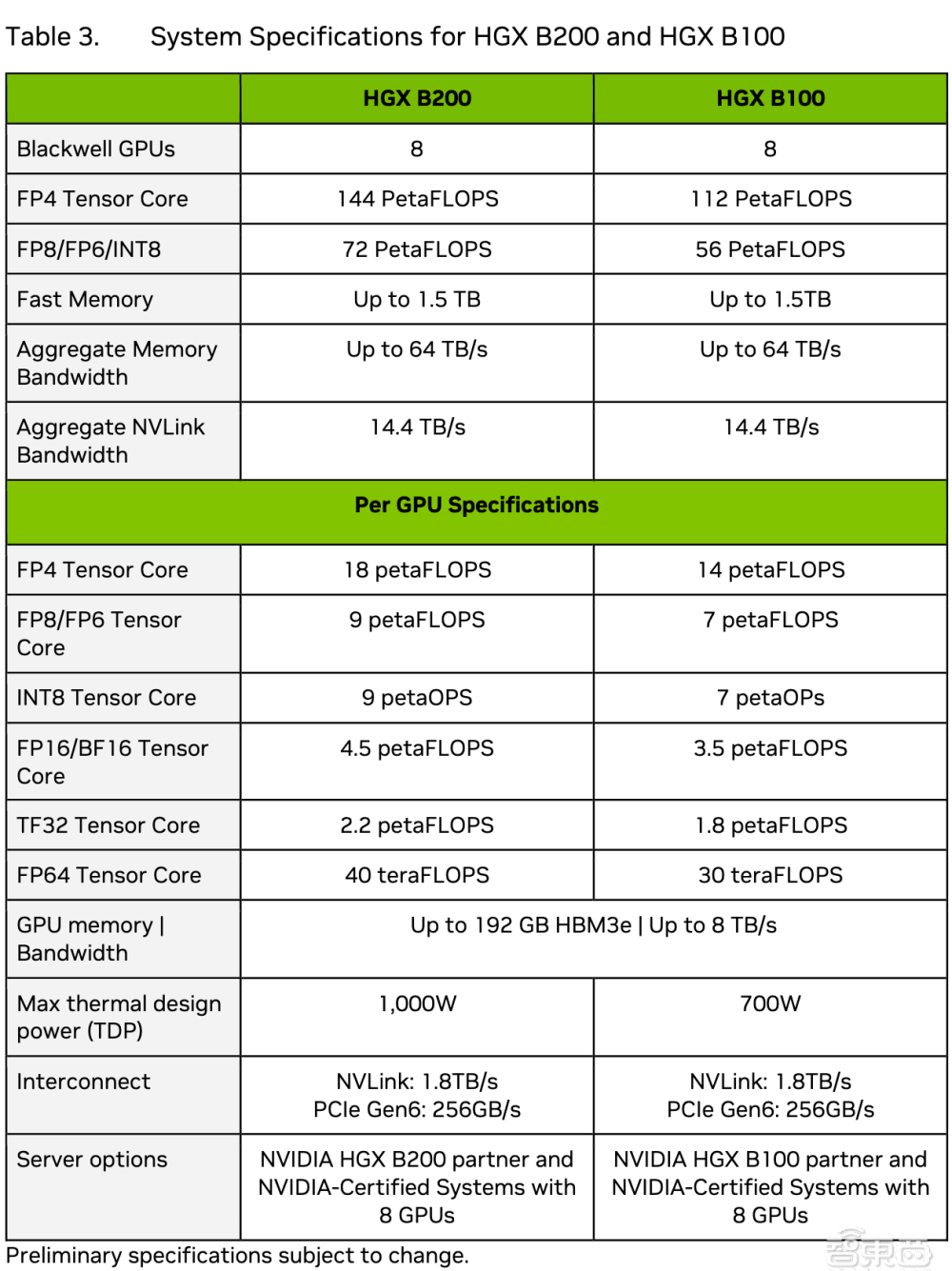
詳解最強AI晶片架構:英偉達Blackwell GPU究竟牛在哪?現場對話技術高管

說起中央電視的主持人,很多人第一個想到的就是董卿了吧。今天小編就來盤點下董卿的6任風流情史。
關心男人工作辛苦暖心的句子?你需要個擁抱或者肩膀,我都在。我的超人,你要是累了,完全可以什麼都不用管,一切有我。你放鬆一下也沒有關係,我會在你休息的時候為你保駕...
日語文案溫柔超仙短句?1.世界欠你的溫容我來給。2.請你當我手心裡的寶。3.書一筆清遠,盈一懷暖陽。4.沒有遺憾,給你再多幸福也不會體會快樂。5.要學會糊塗,別...
曾經的春晚就像一個造星舞臺,捧紅了一波又一波的人。作為一檔全世界都在關注的節目,很多明星都把上春晚,當做自己的人生目標。靠著春晚,很多人的事業都發生了天翻地覆的變化,從默默無聞一舉名揚天下,至今還在蒸蒸日上。
摩托車文案短句高階感?①1.上坡如存錢,下坡如花錢上坡有多累,下坡有多爽。 2.一個人騎車可以騎得更快,一群人騎車可以騎得更遠! 3.騎行不在乎目的地,在乎沿途...…
近日,室溫超導概念在股市比較火爆,很多投資者也開始關注相關的室溫超導概念股票,那麼室溫超導概念股票有哪些呢?
寸止挑戰,是指p站裡的一個影片引發的挑戰,男生按照影片的節奏進行自我安慰。
rap diss語錄?懟人的押韻句子rap如下:一、腦子是個日用品,希望你不要把它當成裝飾品。二、我給你的東西你得珍惜,特別是臉。三、你瞪我的樣子,跟我家狗討食...
最暖心的韓語情話短句有哪些?①나 를 용 서해 무표정 하 게 지 켜 보 는 사랑 너 가 깊다. 原諒我面無表情 卻愛你很深②사랑해, 너랑 있음, 내맘이...
win10截圖快捷鍵win+shift+s沒有反應怎麼解決?
微信變成英文了,怎麼改回中文. 把手機拿給別人用,卻不小心把微信的語言文字變成英文了,那麼要怎麼改回原來的中文模式,如何把語言轉換成中文,為此,本篇先容以下方法,但願可以匡助到你。
作為安卓陣營的真旗艦產品,三星S23 ultra的實力自然無需筆者多言,不管是在螢幕顯示、影像技術、效能水平、續航方面,都能算做安卓陣營的頂尖,也算是保住了三星安卓機皇的“榮光”。雖說它的價格並不美麗,國行動輒上萬的價格,也不是每一個消費者都買得起的,但是S23 ultra依然成為了熱銷單品。
蘋果今天凌晨正式釋出了iOS16.5首個預覽版,不少果粉感嘆道才釋出的iOS16.4,為何這麼快釋出iOS16.5呢?又有哪些最佳化呢?下面就給大家分享首批忠實果粉升級iOS16.5的體驗感慨感染。
在傳統的攝影圈中,都有這樣一個共識,再好的手機拍照效能也趕不上相機。主要原因是手機需要控制厚度與重量,無法把最提高前輩的部件裝進去。手機攝影,與單反無法對比這是事實,但近年來其拍照水平有了具大的提升。特別有了晶片與演算法的加持,成像效果已經可以滿足大多數使用場景。所以,很多朋友在購買手機時,會越來越重視影視功能。
並不是所有的使用者都追求高效能的旗艦手機,也有很多使用者選擇2000元以內的手機,這些手機的價效比比較出色,擁有強大的續航能力和優秀的效能,甚至在某些方面並不比旗艦手機差,在這些高性價比手機當中有三款非常出色,它們的質量都很強,而且有兔兔安的出色資料作為背書,仍是有一定信服力的。在二零二二年九月份當中,兔兔安根據2000元以下的手機進行了排名,排名前三的分別是OPPO K9 Pro,一加Ace競速版,Redmi Note11T Pro,接下來小編將詳細的介紹這三款手機。
Win11工作列怎麼透明?
AI時代帶來的巨大機遇需要產業協同發力、生態協同發展。
[CNMO科技訊息]根據IDC最新公佈的資料,榮耀以17.1%的市場份額登頂國內手機市場。而據CNMO瞭解,榮耀在高階手機市場的增長也非常強勁。有數碼博主公佈資料稱,榮耀Magic6系列首銷第一季度出貨量超過上一代產品首銷前兩個季度出貨量之和。此外,在摺疊屏機型的助攻下,榮耀在600美元以上高階手機市場的出貨量同比增幅達123.3%。
中國網財經4月24日訊 4月23日,“聚力向新——‘看稅收走基層’”網評品牌活動在湖南湘潭啟動。中國網財經記者跟隨媒體團一起實地走進企業,走入基層一線。第一站,媒體團來到湘潭鋼鐵集團有限公司。
過去多個案例顯示,當一輛擁有輔助駕駛功能的汽車發生車禍,其中各方的責任認定總是要更加困難。這個難題也適用於自動駕駛乘用車(Robotaxi)行業,且因為將駕駛員更換為安全員乃至完全無人,分析起來只會更復雜。
第五屆“五五購物節”4月27日正式開啟。