深度學習三巨頭之一Yann LeCun:大語言模型帶不來AGI
當今世界,Yann LeCun 、Geoffrey Hinton 以及 Yoshua Bengio 三位科學家並稱為深度學習三巨頭。值得注意的是,三巨頭之中,LeCun 對於 AI 發展所持的立場是最為樂觀的。此前在馬斯克提出「人工智慧給人類文明帶來了潛伏風險」時,LeCun 曾公然反駁,以為人工智慧遠未發展到給人類構成威脅的程度。關於 AI 接下來該如何發展,在今天上午於北京舉行的 2023 智源人工智慧大會上,他發表了名為《走向能夠學習、推理和規劃的大模型》的演講,表達了系統的思索。
法國當地時間凌晨四點,LeCun 從法國的家中連線智源大會的北京現場。儘管 OpenAI 的 GPT 路線風頭正盛,很多人以為大語言模型將通往 AGI,LeCun 卻直言不諱:需要拋卻天生模型、強化學習方法這樣的主流路線。他以為,基於自監視的語言模型無法獲得關於真實世界的知識。儘管語言天生的內容質量一直晉升,但是這些模型在本質上是不可控的。對於語言模型的侷限性理解,也基於他此前的一個基本觀點:人類有很多知識是目前無法被語言系統所觸達的。
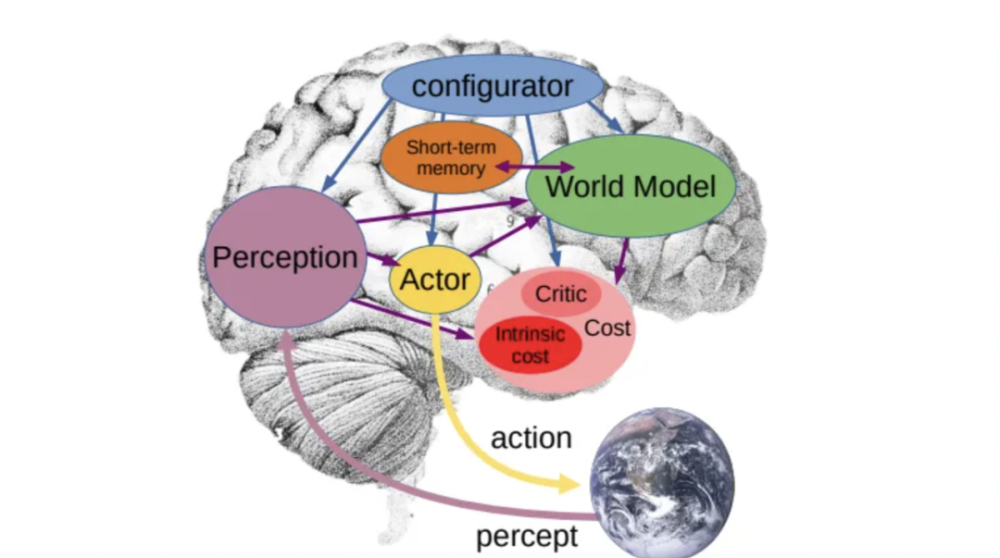
因此,想讓 AI 獲得如人一般對真實世界學習、應對和規劃的能力,他展示了自己在一年前所發表的論文中提出的架構「自主智慧」(autonomous intelligence)。這是由一個配置模組控制整個系統,基於輸入資訊,進行猜測、推理、決議計劃的架構。其中的「世界模組」具有估計缺失資訊、猜測未來外界狀態的能力。
極客公園團隊在智源大會現場觀看了這場演講,以下為核心觀點出色摘要以及經由編纂的演講內容。
LeCun 核心觀點出色摘要:
AI 的能力間隔人類與動物的能力,還有差距——差距主要體現在邏輯推理和規劃,大模型目前只能「本能反應」。什麼是自監視學習?自監視學習是捕獲輸入中的依靠關係。練習系統會捕獲我們看到的部門和我們尚未看到的部門之間的依靠關係。目前的大模型假如練習在一萬億個 token 或兩萬億個 token 的資料上,它們的機能是驚人的。我們很輕易被它的流暢性所疑惑。但終極,它們會犯很愚蠢的錯誤。它們會犯事實錯誤、邏輯錯誤、不一致性,它們的推理能力有限,會產生有害內容。由此大模型需要被重新練習。如何讓 AI 能夠像人類一樣能真正規劃?可以參考人類和動物是如何快速學習的——透過觀察和體驗世界。Lecun 以為,未來 AI 的發展面臨三大挑戰,並由此提出「世界模型(World Model)」。
、

以下為演講全文的部門摘要,經極客公園編纂後釋出:
很負疚我不能親身到場,已經很久沒有去中國了。
今天我將談一下我眼中的人工智慧的未來。我會分享一下 AI 在未來十年左右的方向,以及目前的一些初步結果,但還沒有完整的系統。
本質上來說,人類和動物的能力和今天我們看到的AI的能力之間,是有差距的。簡樸來說,機器學習和人類動物比擬並不特別好。AI 缺失的不僅僅是學習的能力,還有推理和規劃的能力。
過去幾十年來,我們一直在使用監視學習,這需要太多的標註。強化學習效果不錯,但需要大量的實驗。最近幾年,我們更多使用機器自我監視,但結果是,這些系統在某種程度上是專業化和脆弱的。它們會犯愚蠢的錯誤,它們不會推理和規劃,它們只是快速地反應。
那麼,我們如何讓機器像動物和人類一樣理解世界的運作方式,並猜測其步履的後果?是否可以透過無窮步驟的推理執行鏈,或者將複雜任務分解為子任務序列來規劃複雜任務?
這是我今天想講的話題。
但在此之前,我想先談一下什麼是自我監視學習?自我監視學習是捕獲輸入中的依靠關係。在最常見的範例中,我們遮蓋輸入的一部分後將其反饋送到機器學習系統中,然後揭曉其餘的輸入——練習系統會捕獲看到的部門和尚未看到的部門之間的依靠關係。有時是透過猜測缺失的部門來完成的,有時不完全猜測。
這種方法在自然語言處理的領域取得了驚人的成功(如翻譯、文字分類)。最近大模型的所有成功都是這個設法的一個版本。
同樣成功的是生成式人工智慧系統,用於天生影象、影片或文字。在文字領域這些系統是自迴歸的。自監視學習的練習方式下,系統猜測的不是隨機缺失的單詞,而是僅猜測最後一個單詞。系統不斷地猜測下一個標記,然後將標記移入輸入中,再猜測下一個標記,再將其移入輸入中,不斷重複該過程。這就是自迴歸 LLM。
這就是我們在過去幾年中看到的流行模型所做的事情:其中一些來自 Meta 的同事,包括開源的 BlenderBot、Galactica、LLaMA、Stanford 的 Alpaca(Lama 基於 LLaMA 的微調版)、Google 的 LaMDA 、Bard、DeepMind 的 Chinchilla,當然還有 OpenAI 的 ChatGPT 和 GPT-4。假如你將這些模型練習在一萬億個 Token 或兩萬億個 Token 的資料上,它們的機能是驚人的。但終極,它們會犯很愚蠢的錯誤。它們會犯事實錯誤、邏輯錯誤、不一致性,它們的推理能力有限,會產生有害內容。
由於它們沒有關於基礎現實的知識,它們純粹是在文字上進行練習的。這些系統在作為寫作輔助工具、匡助程式設計師編寫程式碼方面非常精彩。但是它們可能會產出虛構的故事或者製造幻覺。
我同事給我開了一個玩笑。他們說,你知道 Yann Lecun(楊立昆)去年發行了一張說唱專輯嗎?我們聽了一下(AI 根據這個設法天生的假專輯),當然這是不真實的,但假如您要求它這樣做,它會這樣做。目前的研究重點是,如何讓這些模型系統能夠調用搜索引擎、計算器、資料庫查詢等這類工具。這被稱為擴充套件語言模型。
我和我的同事合作撰寫過一篇關於擴充套件語言模型的論文。我們很輕易被它們的流暢性所疑惑,以為它們很智慧,但它們實際上並不那麼智慧。它們非常擅長檢索記憶,但它們沒有任何關於世界運作方式的理解。這種自迴歸的天生,存在一種主要缺陷。
假如我們想象所有可能謎底的集合,即標記序列的樹(tree),在這個巨大的樹中,有一個小的子樹對應於給定提示的準確謎底。因此,假如我們想象任何產生標記的均勻機率 e 都會將我們帶出準確謎底集合的集合,而且產生的錯誤是獨立的,那麼它們可能會看到 n 的謎底的相似度是(1-e)的 n 次方。這意味著會存在一個指數級的發散過程將我們帶出準確謎底的樹。這就是自迴歸的猜測過程造成的。除了使 e 儘可能小之外,沒有其他修復方法。
因此,我們必需重新設計系統,使其不會這樣做。這些模型必需重新練習。
那麼如何讓 AI 能夠像人類一樣能真正規劃?我們先來看人類和動物是如何能夠快速學習的。
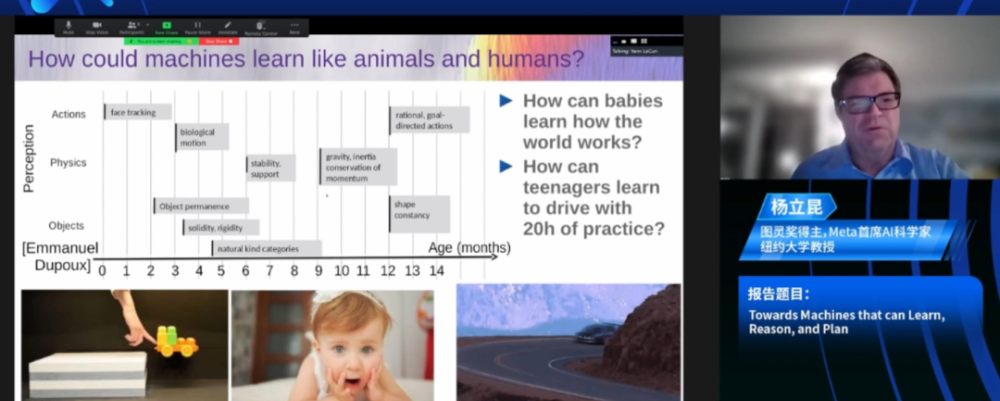
我們看到嬰兒在生命的前幾個月內把握了大量關於世界運作方式的基礎概念:如物體永恆性、世界是三維的、有機和無機物體之間的區別、穩定性的概念、天然種別的學習以及重力等非常基本的概念。嬰兒在 9 個月左右就能會這些。
根據我同事製作的圖表,假如您向 5 個月大的嬰兒展示下面左下角的場景,其中一個小汽車在平臺上,你將小汽車從平臺上推下來,它好像漂浮在空中,5 個月大嬰兒不會感到驚奇。但是 10 個月大的嬰兒會非常驚奇,由於在此期間,嬰兒已經知道了物體不應該停留在空中,它們應該在重力下著落。這些基本概念是透過觀察世界和體驗世界來習得的。我以為我們應該用機器複製這種透過觀察世界或體驗世界學習世界運作方式的能力。
我們有流利的系統,可以透過法律考試或醫學考試,但我們沒有可以清理餐桌並填滿洗碗機的家庭機器人,對吧?這是任何孩子都可以在幾分鐘內學會的事情。但我們仍舊沒有機器可以接近這樣做。
我們顯然在當前擁有的 AI 系統中缺少了非常重要的東西。我們遠遠沒有達到人類水平的智慧,那麼我們該如何做到這一點?實際上,我已經確定了未來幾年 AI 面臨的三個主要挑戰。
首先是學習世界的表徵和猜測模型,當然可以採用自我監視的方式進行學習。
其次是學習推理。這對應著心理學家丹尼爾·卡尼曼的系統 1 和系統 2 的概念。系統 1 是與潛意識計算相對應的人類行為或步履,是那些無需思索即可完成的事情;而系統 2 則是你有意識地、有目的地運用你的全部思維力去完成的任務。目前,人工智慧基本上只能實現系統 1 中的功能,而且並不完全;
最後一個挑戰則是如何透過將複雜任務分解成簡樸任務,以分層的方式執行來規劃複雜的步履序列。
所以大約一年前,我釋出了一篇論文,是關於我以為未來 10 年人工智慧研究應該走向的願景,你可以去看一下,內容基本上是你們在這個演講中聽到的提議。在我提出的這個系統中,核心是世界模型(World Model)。世界模型可以為系統所用,它可以想象一個場景,基於這樣的場景作為依據,猜測步履的結果。因此,整個系統的目的是找出一系列根據其自己的世界模型猜測的步履,能夠最小化一系列本錢的步履序列。
(編者注:有關 Lecun 關於世界模型的論述,感興趣的讀者可以自行搜尋 Lecun 的這篇論文《A Path Towards Autonomous Machine Intelligence》。)
問答環節 Q & A:
提問人:朱軍|清華大學教授,智源首席科學家
Q:生成式模型通常將輸出定義為多個選擇的機率。當我們應用這些天生模型時,我們通常也但願它們擁有創造力,產生多樣化的結果。這是否意味著這些模型實際上無法避免事實錯誤或邏輯的不一致性呢?即使您擁有平衡的資料,由於在很多情況下,資料會產生衝突的影響,對嗎?您之前提到了輸出的不確定性,您對此有何看法?
A:我以為,透過儲存自迴歸天生來解決自迴歸猜測模型天生模型的題目是不可行的。這些系統本質上是不可控的。所以,它們將必需被我提出的那種架構所取代,在推理過程中,你需要讓系統最佳化某種本錢和某些準則。這是使它們可控、可操縱和可規劃的獨一方法。這樣的系統將能夠計劃其回答。
就像我們像現在這樣講話,我們都會計劃講話的過程,怎樣從一個觀點到另一個觀點,怎麼解釋事物,這些都在你的腦海裡。當我們設計演講時,不是一字一句地即興施展。也許在低層次上,我們在即興施展,但在高層次上,我們一定是在規劃。所以規劃的必要性是非常明顯的。人類和很多動物都具備規劃能力,我以為這是智慧的一項重要特徵。所以我的猜測是,在相對短的幾年內,理智的人肯定不會再使用自迴歸元素。這些系統將很快被拋卻,由於它們是無法修復的。
Q:您之後將介入一個辯論,探討人工智慧會不會成為人類生存的威脅。
參會者還有 Yoshua Bengio,Max Tegmark 和 Melanie Mitchell。您能講講您屆時將闡述什麼觀點嗎?

A:在這場辯論中,Max Tegmark 和 Yoshua Bengio 將站在「是」的一邊,以為強盛的 AI 系統可能對人類構成存在風險。而我和 Melanie Mitchell 將站在「否」的一邊。我們的論點不是說沒有風險,而是這些風險固然存在,但透過謹嚴的工程設計可以容易地加以減輕或按捺。
我對此的論點是,今天問人們是否能夠使超智慧系統對人類安全,這個題目無法回答,由於我們還沒有超智慧系統。所以,直到你能基本設計出超智慧系統,你才能討論如何讓它變得安全。這就比如你在 1930 年問一位航空工程師,你能使渦噴發動機安全可靠嗎?工程師會說,什麼是渦噴發動機?由於渦噴發動機在 1930 年還沒有被髮明出來,對吧?所以,我們處於一種有點尷尬的境地。現在,宣稱我們無法使這些系統安全還為時過早,由於我們還沒有發明出它們。一旦我們發明了它們,或許就是按照我所提出的設計藍圖,再討論如何使它們安全也許是值得的。
深度學習三巨頭之一Yann LeCun:大語言模型帶不來AGI
當今世界,Yann LeCun 、Geoffrey Hinton 以及 Yoshua Bengio 三位科學家並稱為深度學習三巨頭。值得注意的是,三巨頭之中,LeCun 對於 AI 發展所持的立場是最為樂觀的。此前在馬斯克提出「人工智慧給人類文明帶來了潛伏風險」時,LeCun 曾公然反駁,以為人工智慧遠未發展到給人類構成威脅的程度。關於 AI 接下來該如何發展,在今天上午於北京舉行的 2023 智源人工智慧大會上,他發表了名為《走向能夠學習、推理和規劃的大模型》的演講,表達了系統的思索。
法國當地時間凌晨四點,LeCun 從法國的家中連線智源大會的北京現場。儘管 OpenAI 的 GPT 路線風頭正盛,很多人以為大語言模型將通往 AGI,LeCun 卻直言不諱:需要拋卻天生模型、強化學習方法這樣的主流路線。他以為,基於自監視的語言模型無法獲得關於真實世界的知識。儘管語言天生的內容質量一直晉升,但是這些模型在本質上是不可控的。對於語言模型的侷限性理解,也基於他此前的一個基本觀點:人類有很多知識是目前無法被語言系統所觸達的。
因此,想讓 AI 獲得如人一般對真實世界學習、應對和規劃的能力,他展示了自己在一年前所發表的論文中提出的架構「自主智慧」(autonomous intelligence)。這是由一個配置模組控制整個系統,基於輸入資訊,進行猜測、推理、決議計劃的架構。其中的「世界模組」具有估計缺失資訊、猜測未來外界狀態的能力。
極客公園團隊在智源大會現場觀看了這場演講,以下為核心觀點出色摘要以及經由編纂的演講內容。
LeCun 核心觀點出色摘要:
AI 的能力間隔人類與動物的能力,還有差距——差距主要體現在邏輯推理和規劃,大模型目前只能「本能反應」。什麼是自監視學習?自監視學習是捕獲輸入中的依靠關係。練習系統會捕獲我們看到的部門和我們尚未看到的部門之間的依靠關係。目前的大模型假如練習在一萬億個 token 或兩萬億個 token 的資料上,它們的機能是驚人的。我們很輕易被它的流暢性所疑惑。但終極,它們會犯很愚蠢的錯誤。它們會犯事實錯誤、邏輯錯誤、不一致性,它們的推理能力有限,會產生有害內容。由此大模型需要被重新練習。如何讓 AI 能夠像人類一樣能真正規劃?可以參考人類和動物是如何快速學習的——透過觀察和體驗世界。Lecun 以為,未來 AI 的發展面臨三大挑戰,並由此提出「世界模型(World Model)」。
、
























