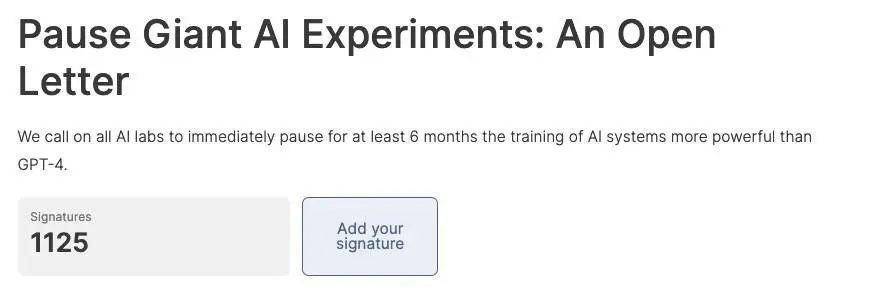
該聯名信已經獲得了包括 2018 年圖靈獎得主 Yoshua Bengio、馬斯克、史蒂夫 · 沃茲尼亞克、Skype 聯合創始人、Pinterest 聯合創始人、Stability AI CEO 等多位知名人士的簽名支援,截稿前聯名人數已經達到 1125 人。附上本封聯名信的地址,感興趣的朋友也可以去簽上自己的名字。????????
https://futureoflife.org/open-letter/pause-giant-ai-experiments/?continueFlag=d19c796896f3776241c518f8747afa68公開信的原文如下:人工智慧具有與人類競爭的智慧,這可能給社會和人類帶來深刻的風險,這已經透過大量研究 [1] 得到證實,並得到了頂級 AI 實驗室的認可 [2]。正如廣泛認可的阿西洛馬爾人工智慧原則(Asilomar AI Principles)所指出的,提高前輩的 AI 可能代表地球生命歷史上的重大變革,因此應該以相應的關注和資源進行規劃和管理。不幸的是,即使在最近幾個月, AI 實驗室在開發和部署越來越強大的數字化思維方面陷入了失控的競爭,而沒有人能夠理解、預測或可靠地控制這些數字化思維,即使是它們的創造者也無法做到這一點。現代 AI 系統現在已經在通用任務方面具有與人類競爭的能力 [3],我們必須問自己:
我們應該讓機器充斥我們的資訊渠道,傳播宣傳和謊言嗎?
我們應該將所有工作都自動化,包括那些令人滿意的工作嗎?
我們應該發展可能最終超過、取代我們的非人類思維嗎?
我們應該冒失控文明的風險嗎?
這些決議計劃不應該由非選舉產生的科技領導人來負責。只有當我們確信AI系統的影響是積極的,風險是可控的,我們才應該開發強大的AI系統。這種決心信念必須得到充分的理由,並隨著系統潛在影響的增大而增強。OpenAI 最近關於人工智慧的宣告指出:「在某個時候,可能需要在開始訓練未來系統之前獲得獨立審查,對於最提高前輩的努力,需要同意限制用於建立新模型的計算增長速度。」我們同意。現在就是那個時刻。因此,我們呼籲所有 AI 實驗室立即暫停至少 6 個月的時間,不要訓練比 GPT-4 更強大的 AI 系統。這個暫停應該是公開和可驗證的,幷包括所有關鍵參與者。如果無法迅速實施這樣的暫停,政府應該介入並實行一個暫禁令。AI 實驗室和獨立專家應該利用這個暫停時間共同制定和實施一套共享的提高前輩 AI 設計和開發安全協議,這些協議應該由獨立的外部專家嚴格稽核和監督。這些協議應確保遵守它們的系統在合理懷疑範圍之外是安全的 [4]。這並不意味著暫停 AI 發展,而只是從不斷邁向更大、不可預測的黑箱模型及其突現能力的危險競賽中退一步。AI 研究和開發應該重點放在提高現有強大、提高前輩系統的準確性、安全性、可解釋性、透明度、魯棒性、對齊、可信度和忠誠度。與此同時,AI 開發者必須與政策制定者合作,大力加速 AI 管理體系的發展。這些至少應包括:專門負責 AI 的新的、有能力的監管機構;
對高能力 AI 系統和大型計算能力池的監督和跟蹤;
用於區分真實與合成內容、跟蹤模型洩漏的溯源和水印系統;
健全的審計和認證生態系統;對 AI 造成的損害承擔責任;
技術AI安全研究的充足公共資金;
應對 AI 引起的巨大經濟和政治變革(特別是對民主制度的影響)的資深機構。
人類可以在 AI 的幫助下享受繁榮的未來。在成功創造出強大的 AI 系統之後,我們現在可以享受一個「AI 盛夏」,在其中我們收穫回報,將這些系統明確地用於造福所有人,並讓社會有機會適應。在面臨可能對社會造成災難性影響的其他技術上,社會已經按下了暫停鍵 [5]。在這裡,我們也可以這樣做。讓我們享受一個漫長的 AI 盛夏,而不是毫無準備地衝向秋天。參考資訊:[1]
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?????. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency (pp. 610-623).
Bostrom, N. (2016). Superintelligence. Oxford University Press.
Bucknall, B. S., & Dori-Hacohen, S. (2022, July). Current and near-term AI as a potential existential risk factor. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society (pp. 119-129).
Carlsmith, J. (2022). Is Power-Seeking AI an Existential Risk?. arXiv preprint arXiv:2206.13353.
Christian, B. (2020). The Alignment Problem: Machine Learning and human values. Norton & Company.
Cohen, M. et al. (2022). Advanced Artificial Agents Intervene in the Provision of Reward. AI Magazine, 43(3) (pp. 282-293).
Eloundou, T., et al. (2023). GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models.
Hendrycks, D., & Mazeika, M. (2022). X-risk Analysis for AI Research. arXiv preprint arXiv:2206.05862.
Ngo, R. (2022). The alignment problem from a deep learning perspective. arXiv preprint arXiv:2209.00626.
Russell, S. (2019). Human Compatible: Artificial Intelligence and the Problem of Control. Viking.
Tegmark, M. (2017). Life 3.0: Being Human in the Age of Artificial Intelligence. Knopf.
Weidinger, L. et al (2021). Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359.[2]
Ordonez, V. et al. (2023, March 16). OpenAI CEO Sam Altman says AI will reshape society, acknowledges risks: "A little bit scared of this". ABC News.
Perrigo, B. (2023, January 12). DeepMind CEO Demis Hassabis Urges Caution on AI. Time.[3]
Bubeck, S. et al. (2023). Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv:2303.12712.
OpenAI (2023). GPT-4 Technical Report. arXiv:2303.08774.[4]
Ample legal precedent exists – for example, the widely adopted OECD AI Principles require that AI systems "function appropriately and do not pose unreasonable safety risk"[5]
Examples include human cloning, human germline modification, gain-of-function research, and eugenics.